




A inteligência artificial (IA) é o tema tecnológico do momento graças ao seu potencial transformador de praticamente tudo o que conhecemos. ...
A inteligência artificial (IA) é o tema tecnológico do momento graças ao seu potencial transformador de praticamente tudo o que conhecemos.

Mas o que é afinal inteligência artificial? Há cerca de vinte anos fiz essa pergunta para meus alunos de computação na UNIP - Campus Brasília. Resolvi mostrar o que era isso através de algo que quase todos ali gostavam e se interessavam do ponto de vista da programação, através de um jogo.


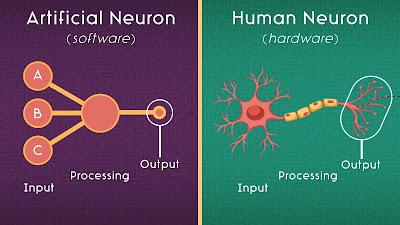
 Em uma tentativa de se imitar a natureza, sem com isso cravar que os neurônios biológicos funcionam exatamente assim, os neurônios artificiais são funções programadas que recebem dados de outros neurônios artificiais e que por meio de uma fórmula transformam esses dados e fornece uma saída para outra camada de neurônios artificiais e assim sucessivamente. Formando assim uma rede de neurônios artificiais. A rede neural artificial que doravante vou me referir apenas como rede neural.
Em uma tentativa de se imitar a natureza, sem com isso cravar que os neurônios biológicos funcionam exatamente assim, os neurônios artificiais são funções programadas que recebem dados de outros neurônios artificiais e que por meio de uma fórmula transformam esses dados e fornece uma saída para outra camada de neurônios artificiais e assim sucessivamente. Formando assim uma rede de neurônios artificiais. A rede neural artificial que doravante vou me referir apenas como rede neural.
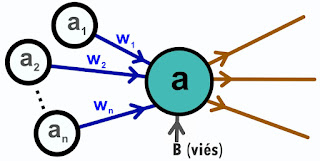

Esses pesos e viéses são modificados durante o aperfeiçoamento dessa rede neural (denominado “treinamento”) até que a entrada no sistema produza uma saída esperada. Esses pesos e tendências são denominados parâmetros e a quantidade desses parâmetros passou a ser uma espécie de medida do potencial de inteligência de uma rede neural (quanto mais parâmetros um sistema possuir maior a inteligência em potencial).

Ou seja, o que você aprendeu já serve para acompanhar e se posicionar melhor em tretas acadêmicas.😝


Experimentando IA em um jogo
Para que todos tivessem acesso pela internet ao experimento adaptei um jogo Connect 4 (conhecido no Brasil por Ligue 4 ou Conecta 4) em javascript e ASP onde um jogador humano poderia jogar contra o computador. As regras são bem simples: Cada jogador teria peças de uma cor (azul e vermelho, por exemplo) Um tabuleiro 7 colunas x 6 linhas permite que cada oponente, na sua vez, escolha uma das 7 colunas que tenha uma casa vazia.
Assim uma peça do jogador seria alojada na casa vazia mais próxima da base da coluna escolhida. Caso aquela peça forme uma linha de 4 peças da mesma cor na horizontal, vertical ou diagona o jogador vence a partida.
É semelhante ao Jogo da Velha com a diferença que em vez de três o jogador deve ter quatro casas ocupadas alinhadas para vencer a partida. Além disso, o tabuleiro físico do Connect 4 é vertical e as peças caem para base pela força da gravidade. O que muitas vezes é simulado nas versões digitais por alguma animação onde a peça é colocada no topo e escorrega para a base.
 |
O jogo não existe mais. Resta esse snapshot de como era o portal Gomes Home Page na época (por Wayback Machine).
Pois bem, nesse experimento o computador sorteia a coluna onde irá jogar com uma diferença: Caso perca a partida ele armazena a sequência das jogadas daquela partida em uma estrutura de dados que na computação é chamada de árvore. E essa árvore é usada para decidir onde NÃO jogar em partidas futuras.
Com isso o computador consegue realizar algumas coisas que normalmente só creditamos a seres ditos inteligentes. Ele APRENDE com seus erros e ele TOMA DECISÕES que podemos considerar eficazes. E quanto mais jogadas ele armazena em sua árvore mais eficaz é sua decisão.
Conceituando Inteligência
Aqui cabe a pergunta: Afinal, o que é inteligência? Só essa questão já é controversa o suficiente e exigiria vários posts tentando se chegar a um consenso que sequer os especialista logram. Mas a Wikipedia nos dá uma pista, informando que o termo vem do latim intellectus, de intelligere = inteligir, entender, compreender. Composto de íntus = dentro e lègere = recolher, escolher, ler.
Quando existe mais de um “consenso” para alguma definição isso já denota um problema em si. Como o meu objetivo aqui é promover o entendimento vou usar a minha intuição de professor e usar uma definição muito simples e bem explicada da Enciclopédia Disney de 1974 (sim, é para crianças, mas ainda assim é muito boa para a compreensão. Caso queira dezenas de outras veja o artigo A Collection of Definitions of Intelligence).
Ainda segundo ela, existem dois “consensos” de definição de inteligência:
- O primeiro, de Intelligence: Knowns and Unknowns, um relatório de uma equipe congregada pela Associação Americana de Psicologia, em 1995.
- E o segundo de Mainstream Science on Intelligence, que foi assinada por cinquenta e dois pesquisadores em inteligência (de 131 cientistas convidados), em 1994.
- [accordion]
- Conceito de inteligência segundo Enciclopédia Disney, 1974
- A capacidade de resolver problemas.
- Consenso sobre inteligência de Intelligence: Knowns and Unknowns, 1995
- “Os indivíduos diferem na habilidade de entender ideias complexas, de se adaptarem com eficácia ao ambiente, de aprenderem com a experiência, de se engajarem nas várias formas de raciocínio, de superarem obstáculos mediante o pensamento. Embora tais diferenças individuais possam ser substanciais, nunca são completamente consistentes: o desempenho intelectual de uma dada pessoa vai variar em ocasiões distintas, em domínios distintos, a se julgar por critérios distintos. Os conceitos de 'inteligência' são tentativas de aclarar e organizar esse conjunto complexo de fenômenos.”
- Consenso sobre inteligência de Mainstream Science on Intelligence, 1994
- “uma capacidade mental bastante geral que, entre outras coisas, envolve a habilidade de raciocinar, planejar, resolver problemas, pensar de forma abstrata, compreender ideias complexas, aprender rápido e aprender com a experiência. Não é uma mera aprendizagem literária, uma habilidade estritamente acadêmica ou um talento para sair-se bem em provas. Ao contrário disso, o conceito refere-se a uma capacidade mais ampla e mais profunda de compreensão do mundo à sua volta - 'pegar no ar', 'pegar' o sentido das coisas ou 'perceber' uma coisa.”
Nela o Prof. Ludovico (um pato) diz a Donald (outro pato) e seus sobrinhos (que não chegavam a um consenso sobre a definição) que inteligência, para os psicólogos, seria simplesmente:
“A capacidade de resolver problemas.”
 |
| A Enciclopédia Disney discorria sobre o conceito de inteligência em 1974. |
Talvez isso estivesse mais próximo da realidade em 1974, antes da teoria das inteligências múltiplas, o fato é que essa definição nos permite avançar. Ludovico, o personagem intelectual, mostrou que uma forma de se medir a inteligência animal era propor um experimento onde aves eram colocadas em uma caixa com dois discos coloridos onde ao se tocar em um deles o animal conseguia alimento.
Assim o número de tentativas ao acaso que o animal executasse até associar o disco correto com o alimento seria uma medida inversa de inteligência. Ou seja, quanto MENOS demorasse para aprender como os discos funcionavam, maior a inteligência.
Mamíferos, em média, normalmente demoraria menos tempo ainda para entender como um experimento como esse funciona e qual deveria ser o procedimento para obter o alimento. Por isso diríamos que os mamíferos são mais inteligentes que as aves.
De posse dessa definição cabe agora a outra pergunta, o que é inteligência artificial. Uma popular e inicial definição, foi introduzida por John McCarthy na famosa conferência de Dartmouth em 1956. Para McCarthy IA seria:
“Fazer a máquina comportar-se de tal forma que seja chamada inteligente caso fosse este o comportamento de um ser humano.”
Parece meio simplório mas talvez sirva. Um ponto interessante é que a IA, segundo essa definição, deve ser comparada ao ser humano. Será que se uma máquina jogar xadrez melhor que um pombo ou dirigir um carro melhor que uma capivara não poderia ser considerada inteligente? Essas definições ajudam a separar os conceitos do que seria o estado da arte em IA hoje em dia.
Por exemplo, o que um monte de comando If...then (Se...Então) difere de uma rede neural – uma tentativa de se imitar o cérebro humano artificial por meio de neurônios artificiais, como veremos mais adiante.
Por exemplo, o que um monte de comando If...then (Se...Então) difere de uma rede neural – uma tentativa de se imitar o cérebro humano artificial por meio de neurônios artificiais, como veremos mais adiante.
Para que fique fácil de entender. Se ao invés de um Connect 4 eu estivesse programando um Jogo da Velha e colocasse todas as possbilidades de jogadas com o comando Se (que é o principal comando geralmente usado para tomar decisões lógicas em uma linguagem). Seria algo como:
[Se o jogador colocou X na casa 1
Então eu coloco O na casa 5
Se o jogador colocou X na casa 2
Então eu coloco O na casa 5
...
Se o jogador colocou X na casa 5
Então eu coloco O na casa 1
...
]

Ou seja, você teria que prever todas as jogadas possíveis para programar a decisão de cada jogada do computador. É parecido com a ideia da árvore onde cada galho representa uma jogada possível após outra sequência de jogadas dos galhos anteriores. Isso é até possível em um jogo simples como o Jogo da Velha (o que pode ser melhorado com uma árvore Minimax) mas se torna impraticável em um jogo como o xadrez com muito mais possibilidades ou em situações como dirigir um carro autônomo.

Árvore representando o algoritmo Minimax (Canal Spanning Tree)
No exemplo do Connect 4 (⬤ Ligue 4 ⬤), com o aprendizado que programei em 2003 para a demonstração, o jogo vai aprendendo com as derrotas do computador – a cada derrota, a jogada perdedora é armazenada e nunca mais se repete da mesma forma pois o computador “aprendeu” com a derrota.
Rede Neural
Outra maneira de proporcionar aprendizado às máquinas é através de redes neurais artificiais. Com a rede neural tudo ocorre de forma diferente. Remetendo à biologia, a célula nervosa que recebe, processa e transmite impulsos nervosos (na forma de eletricidade) é também conhecido como neurônio. O neurônio biológico que compõe nosso cérebro recebe vários estímulos elétricos de entrada (input), faz alguma transformação com esses dados em seu núcleo e fornece estímulos elétricos a vários outros neurônios conectados a ele através das sinapses.

Como um neurônio artificial se compara a um biológico. (Canal Code.org)

Esses dados de entrada possuem pesos (representado por W, pois vem do inglês weight) e a fórmula usada em cada neurônio artificial ainda sofre a influência de um valor, chamado tendência (também chamados de desvio, ou ainda viés, e é representado por B, do inglês bias).

Assim, uma rede neural é composta por neurônios organizados em camadas que são de três tipos: entrada, ocultas e saída. Cada neurônio será ativado ou não com base na saída de sua função de ativação (cujo valor resultante é representado pela letra “a”), que recebe todos os valores e pesos de entrada junto com uma tendência e calcula um número entre -1 e 1 ou 0 e 1. Este valor é passado para os neurônios da próxima camada através de um processo chamado propagação direta. As camadas ocultas determinam a profundidade da rede, relacionada ao conceito de deep learning (“aprendizado profundo”). O número de camadas ocultas é limitado apenas pelo poder de processamento disponível.

Animação mostrando um exemplo de rede neural a ser treinada.
A diferença entre a saída esperada na camada de saída da rede neural e a saída que está sendo obtida de fato é calculada pela função de Perda (também chamado de Custo). Tudo que ela faz efetivamente é somar os quadrados de todas as diferenças nos neurônios da camada de saída. Dizendo de outra forma, a função de Perda nos informa o nível de precisão de nossa rede neural quando essa rede tenta fazer previsões para uma determinada entrada.
Quando os dados usados nas entradas de treinamento nessa rede neural resultar nas saídas esperadas, isto é, quando a Perda for aceitável, diz-se que a rede está treinada. Ocorre então a chamada machine learning (aprendizado de máquina). E é assim, por aproximação estatística, que o computador com esse tipo de programação aprende e toma decisões.
Quando os dados usados nas entradas de treinamento nessa rede neural resultar nas saídas esperadas, isto é, quando a Perda for aceitável, diz-se que a rede está treinada. Ocorre então a chamada machine learning (aprendizado de máquina). E é assim, por aproximação estatística, que o computador com esse tipo de programação aprende e toma decisões.
Você se lembra dos parâmetros? Em geral, pesos e tendências são definidos inicialmente com valores aleatórios, o que normalmente leva a um valor alto de Perda quando se inicia o treinamento de uma rede neural. O objetivo é minimizar essa perda e é aqui que entra a chamada retropropagação.
Cada ciclo completo de propagação direta e ajuste através da retropropagação é chamado de época. O objetivo é minimizar a função de Perda, tornando a rede mais precisa. Este processo é computacionalmente intenso e só se tornou prático recentemente devido aos avanços no poder de processamento dos computadores.
Retropropagação
O aprendizado em redes neurais ocorre principalmente através de um processo chamado retropropagação. Nesse processo, a saída da rede é comparada com a saída desejada usando a função de Perda que quantifica o erro entre a saída prevista e a real. Os pesos e desvios nos neurônios são então ajustados para minimizar esse erro.Cada ciclo completo de propagação direta e ajuste através da retropropagação é chamado de época. O objetivo é minimizar a função de Perda, tornando a rede mais precisa. Este processo é computacionalmente intenso e só se tornou prático recentemente devido aos avanços no poder de processamento dos computadores.
Se uma rede dessas tiver entradas em um número suficientemente grande de dados, passa a ser muito provável então que uma entrada diferente das entradas usadas no treinamento resulte em um resultado novo e ainda assim correto. Aí o sistema passa a fazer coisas novas que um sistema cheio de IFs e THENs não conseguiria.
Para exemplificar, imagine que esteja sendo treinado uma rede neural para que carros autônomos reconheçam pedestres em uma imagem captada por uma das câmeras do veículo. A imagem então seria passada para os neurônios da entrada da rede neural que fracionaria a imagem e passaria para outra camada de neurônios que separaria os elementos da imagem (rosto, tronco, membros, etc) e tentaria identificar as coisas na imagem (pessoas, árvores, estrada, etc).
Os desenvolvedores dessa rede neural então supervisionariam cada tentativa de se identificar uma pessoa na imagem e, naquelas tentativas que não fossem bem sucedidas, iriam mudar os pesos e tendências até que, após centenas ou milhares de vezes, o computador passasse a identificar corretamente os pedestres.

Um simulador de rede neural (Neural Network Playground)
Depois, quando submetido a imagens que não foram usadas no treino, é muito provável que o computador consiga detectar, com alto grau de precisão, pedestres que o sistema nunca tivera contato. Desde que o enorme conjunto de imagens usado no treinamento seja representativo da realidade que o computador terá contato quando for reconhecer os indivíduos na prática.
Transformer (a base do ChatGPT)
Felizmente, técnicas mais apuradas são frequentemente desenvolvidas para que a precisão seja ainda mais alta e o processamento de dados seja viável. Assim, em 2017, pesquisadores da Google descreveram em um artigo (Attention Is All You Need, 2017) o modelo Transformer. O modelo Transformer (Tranformador) é uma rede neural que aprende o contexto e, assim, o significado com o monitoramento de relações em dados sequenciais como as palavras desta frase. Na verdade ele analisa unidades que podem ser menores ainda que palavras, como um pequeno conjunto de letras chamado “token”.
Funciona parecido com o autocompletar de um teclado de celular. Você digita uma palavra e o modelo sugere a próxima palavra baseado nas estatísticas do que seria o mais usual. Por exemplo, você digita “inteligência” e ele sugere “artificial” por ser uma combinação de palavras muito comum.
Funciona parecido com o autocompletar de um teclado de celular. Você digita uma palavra e o modelo sugere a próxima palavra baseado nas estatísticas do que seria o mais usual. Por exemplo, você digita “inteligência” e ele sugere “artificial” por ser uma combinação de palavras muito comum.
Segundo o blog da NVidia, essa tecnologia aplica um conjunto em evolução de técnicas matemáticas, chamadas de atenção ou autoatenção, para detectar as maneiras sutis como até mesmo palavras distantes (na verdade “tokens”) de uma série sendo escrita influenciam e dependem umas das outras.
Para se ter uma ideia, um chatbot convincente para dialogar por meio de texto em liguagem natural, treinado com os dados da internet pública inteira até 2021 – além de provedores de dados privados como o GitHub, um repositório de códigos de programação – , como o ChatGPT usa modelos Transformers (GPT significa Transformador Generativo Pré-treinado). O GPT-3.5 possui 176 bilhões de parâmetros. Já o modelo GPT-4 , lançado em 2023 e disponível para a versão paga do ChatGPT, não teve a quantidade de parâmetros divulgada pela OpenAI (a empresa desenvolvedora do ChatGPT) mas provavelmente é algo entre 1 trilhão e 100 trilhões de parâmetros.
Já vimos que é necessário treinar um modelo como esse o que exige muitos dados e formas de validar os resultados com estratégia muito variadas. Assim, uma maior quantidade de parâmetros torna o treino mais desafiador por isso não é garantia de que a quantidade por si só garanta uma superioridade nos resultados. Mas o potencial para se obter uma melhor performance aumenta a expectativa sobre o que mais poderemos esperar dessa tecnologia.
Além de desenvolver e corrigir códigos de programação, traduzir textos e produzir com muito mais precisão e estilo, as novas IAs conseguem produzir imagens, vídeos e até dublar sua voz com sincronia labial em múltiplos idiomas (HeyGen). Isso terá o dom de rapidamente permitir rapidez na produção artística comercial, desenvolver pesquisas que vão de tecnologias bélicas a descobertas da medicina, erodir os postos de trabalho e revolucionar a educação, geolocalizar videoproduções e atentar contra a democracia. Tudo junto e ao mesmo tempo.
O assunto é complexo. Tanto que o material que recomendamos aqui para que você se apronfunde mais no tema também estará cheio de pontos onde caberá estudos ainda mais aprofundados para que se entenda como a inteligência artificial realmente é desenvolvida e empregada. Tudo vai depender do quanto você pretende adentrar nesse universo: Programar, desenvolver e usar sistemas inteligentes ou apenas melhorar a compreensão sobre o hype do momento e desmistificar algumas falácias que também acompanham o debate em torno do assunto.
O que podemos assegurar é que com a corrida das big techs pela supremacia nesse campo de pesquisa multidisciplinar estamos só no começo das colossais transformações sociais e econômicas que elas certamente trarão. É um blend de resultados assustadores e maravilhosos ao mesmo tempo. Prepare o seu coração!
*Agora que você já sabe disso tudo fica mais fácil acompanhar a reação polêmica ao neurocientista Miguel Nicolelis (entrevistado pelo Sérgio Sacani no podcast Ciência sem Fim) pelo professor de Inteligência Artificial da IFRS, Rafael Pinto.
Ou seja, o que você aprendeu já serve para acompanhar e se posicionar melhor em tretas acadêmicas.😝
Alguma dúvida sobre o que foi explicado escreva um comentário abaixo que tentaremos esclarecer melhor.
Com informações de Enciclopédia Disney, Wayback Machine, Leonardo.ai, NVidia, Kaiber.ai, Wikipedia, HeyGen, Revista MSDN, Youtube,
Visto no Brasil Acadêmico
Com informações de Enciclopédia Disney, Wayback Machine, Leonardo.ai, NVidia, Kaiber.ai, Wikipedia, HeyGen, Revista MSDN, Youtube,
Visto no Brasil Acadêmico









{kind=link}
Comentários